AWS provides two methods to access instance metadata (Instance Metadata Service): IMDSv2 and IMDSv1. While both versions are enabled by default, IMDSv2 offers enhanced security through session-oriented requests. This newer version requires a session token for authentication, unlike IMDSv1’s simpler request/response method. For detailed examples and SDK compatibility information, refer to: How to use the Instance Metadata Service to access instance metadata.
Task metadata available for ECS on Amazon EC2
If your Amazon ECS task is hosted on Amazon EC2, you can access task host metadata using the Instance Metadata Service (IMDS) endpoint: http://169.254.169.254/latest/meta-data/
Important: This approach just works in your ECS Task is hosted on Amazon EC2 and not for Fargate.
Using SDK for ECS on Amazon EC2
For example using JavaScript SDK with IMDSv1.
constAWS=require("aws-sdk");constmeta=newAWS.MetadataService();app.get('/',(req,res)=>{constresponse={message:'Response back from Express REST API'};meta.request("/latest/meta-data/local-ipv4",function(err,data){if(err){response.error="Error fetching local IPv4 address";res.status(500).json(response);}else{response.localIpv4=data;res.json(response);}});});
If IMDSv2 is enabled previous code will fail with the following error:
Response back from Express REST API
Error fetching local IPv4 address: Error: null
at IncomingMessage.<anonymous> (/app/node_modules/aws-sdk/lib/util.js:930:34)
at IncomingMessage.emit (node:events:526:35)
at IncomingMessage.emit (node:domain:488:12)
at endReadableNT (node:internal/streams/readable:1408:12)
at process.processTicksAndRejections (node:internal/process/task_queues:82:21) {
statusCode: 401,
retryable: false,
time: 2025-06-11T17:30:50.372Z
}
If you are migrating from IMDSv1 to IMDSv2 using EC2 and JavaScript SDK you need to get first the token and then request the metadata endpoint as followed:
constAWS=require("aws-sdk");constmeta=newAWS.MetadataService();app.get('/',(req,res)=>{console.log('Response back from Express REST API');// Fetching the local IPv4 address from AWS Metadata Serviceconstresponse={message:'Response back from Express REST API'};meta.fetchMetadataToken(function(err,token){if(err){console.error("Error fetching metadata token: ",err);response.error="Error fetching metadata token";res.status(500).json(response);return;}else{meta.request("/latest/meta-data/local-ipv4",{headers:{"x-aws-ec2-metadata-token":token}},function(err,data){if(err){console.error("Error fetching local IPv4 address: ",err);response.error="Error fetching local IPv4 address";res.status(500).json(response);return;}else{console.log("Local IPv4 address: ",data);response.localIpv4=data;res.json(response);}});}});});
Important: This approach just works in your ECS Task is hosted on Amazon EC2 and not for Fargate.
If you run this code in ECS Fargate you won’t find the endpoint, example:
Error fetching local IPv4 address: Error: connect EINVAL 169.254.169.254:80 - Local (0.0.0.0:0)
at internalConnect (node:net:1090:16)
at defaultTriggerAsyncIdScope (node:internal/async_hooks:464:18)
at node:net:1315:9
at process.processTicksAndRejections (node:internal/process/task_queues:77:11) {
errno: -22,
code: 'EINVAL',
syscall: 'connect',
address: '169.254.169.254',
port: 80
}
Task metadata available for Amazon ECS tasks on Fargate
From ECS Fargate you can’t reach the EC2 endpoint 169.254.169.254 directly. In order to query the metadata, you need to use the environment variables endpoints injected into each container in a task. There are different task metadata versions, the latest one is v4. Refer to Amazon ECS task metadata endpoint version 4 for tasks on Fargate. These endpoints can varies depending on the Fargate version you are using (v2,v3,v4).
Using Fargate you can use the following endpoint 169.254.170.2/v4/metadata
Each endpoint will provide similar data or extra fields, review the json structure to get specific data.
${ECS_CONTAINER_METADATA_URI_V4} - Returns metadata for the container.
${ECS_CONTAINER_METADATA_URI_V4}/task - Returns metadata for the task, including a list of the container IDs and names for all of the containers associated with the task.
${ECS_CONTAINER_METADATA_URI_V4}/stats - Returns Docker stats for the Docker container.
Displaying information using endpoint ECS_CONTAINER_METADATA_URI
From the previous output you can get the private ip assigned using this code:
constaxios=require('axios');app.get('/fargate',async(req,res)=>{console.log('Response back from Express REST API for Fargate');constresponse={message:'Response back from Express REST API for Fargate'};constmetadataUrl=process.env.ECS_CONTAINER_METADATA_URI;if(!metadataUrl){response.error="ECS_CONTAINER_METADATA_URI_V4 environment variable not set";returnres.status(500).json(response);}try{constmetaRes=awaitaxios.get(metadataUrl);constmetaData=metaRes.data;response.metadata=metaData;// Extract private IP from Networks[0].IPv4Addresses[0]letprivateIp=null;if(Array.isArray(metaData.Networks)&&metaData.Networks.length>0&&Array.isArray(metaData.Networks[0].IPv4Addresses)&&metaData.Networks[0].IPv4Addresses.length>0){privateIp=metaData.Networks[0].IPv4Addresses[0];}response.privateIp=privateIp;res.json(response);}catch(err){console.error("Error fetching Fargate metadata: ",err);response.error="Error fetching Fargate metadata";res.status(500).json(response);}});
When you’ve lost a Docker image from your remote repository but it’s still cached on a Kubernetes Node, you can recover it using containerd’s command-line tool, ctr. This tool is typically bundled with containerd installations.
Using ctr
ctr, often included in containerd installations, can be used in conjunction with crictl, a standalone kubernetes-sigs project. Here’s how to interact with ctr and containerd:
Set up the environment: To interact with ctr define this environment variable:
In scenarios that you want to run a Daemonset, but want to run daemonset pods in specific nodes or avoid running pods without deleting the daemonset for a particular timeframe. You can use labes with nodeSelector.
The nature of a DaemonSet was designed to run one pod per node in your Kubernetes cluster, if you have 3 nodes, you will see 3 daemonset pods running.
To effectively reduce the number of Daemonset pods to 0 without deleting the DaemonSet or to chose which node will be running the daemonset pods, it is recommended to use Node Selectors. Here are two ways to implement this solution:
Setting Labels to Kubernetes Nodes
Add a label to all existing nodes. In this example I will use “fluent-bit=false” to control how many FluentBit Daemonset pods will be running in my nodes. To add a label use this command:
kubectl get nodes -o name | xargs -I{} kubectl label {} fluent-bit=false --overwrite
Note: You may need to rerun this command if new nodes are added to the cluster.
Verify the label change:
kubectl get nodes --show-labels
Modify your DaemonSet manifest adding a new selector:
To re-enable Daemonset pods in the future, you can update the node labels to a desired label and value. e.g. “fluent-bit=true”:
Patching Node Selectors
Patching on the fly. In this case, the command is setting the nodeSelector to include a label “non-existing”: “true”, which means that the fluent-bit pods will only be scheduled on nodes that have this label.
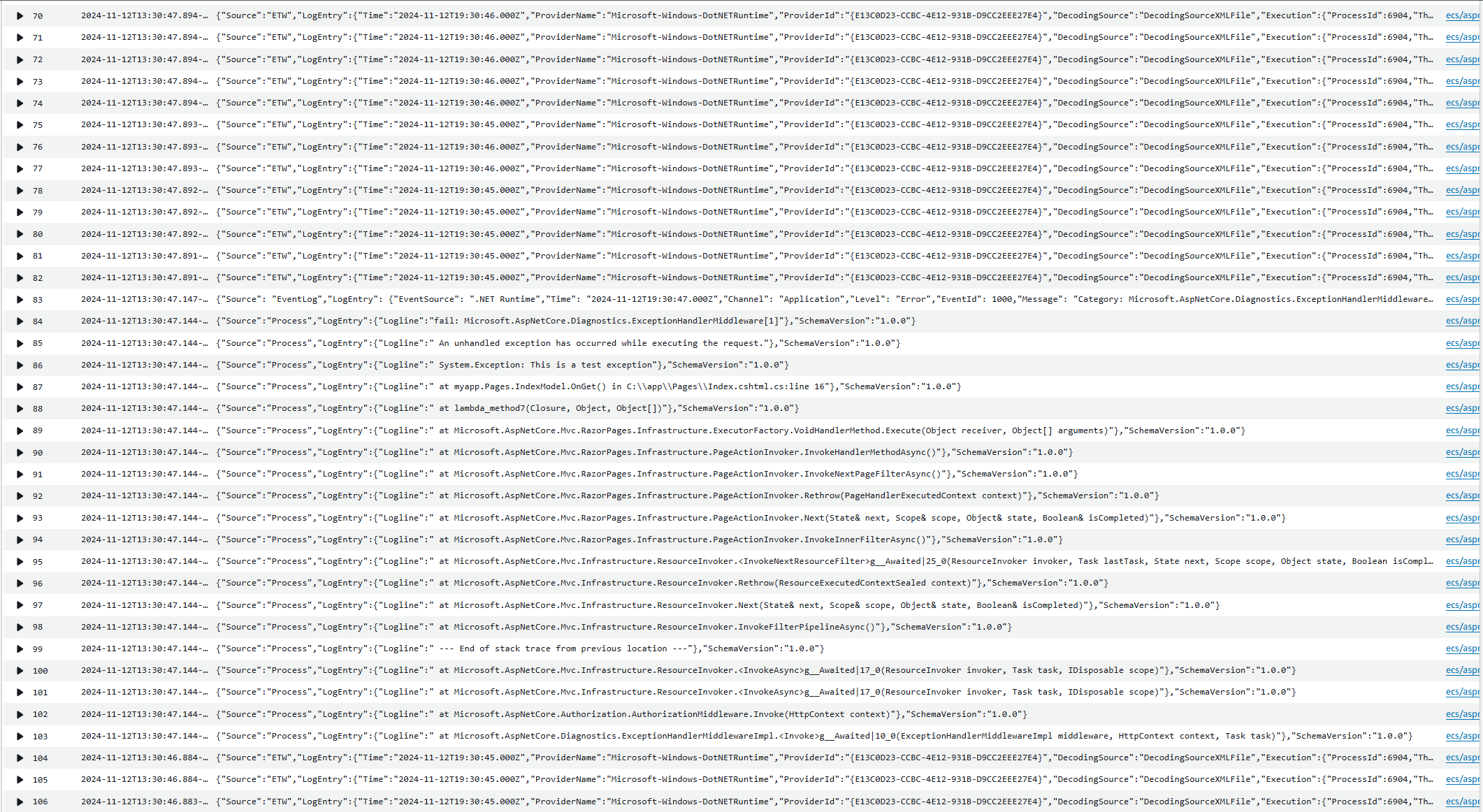
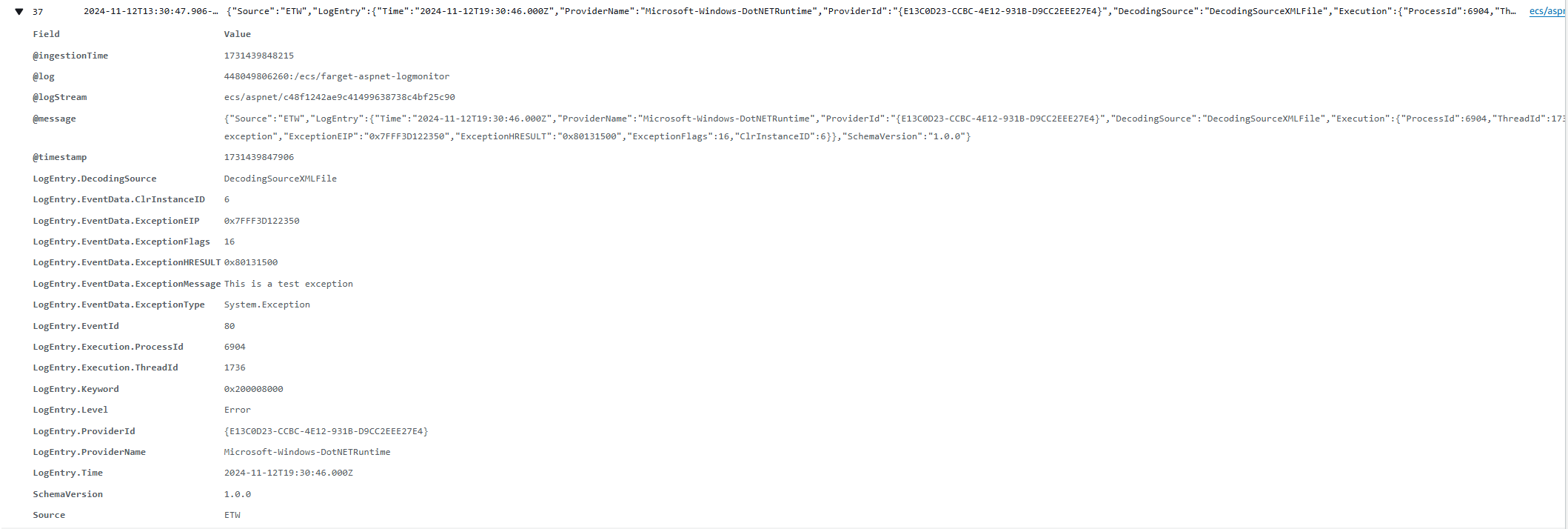
Windows applications often use different logging mechanisms than their Linux counterparts. Instead of relying on STDOUT, Windows apps typically utilize Windows-specific logging methods, such as ETW, the Event Log, or custom log files like IIS logs. If you’re running a Windows container in an ECS cluster and want to capture Windows and IIS logs in CloudWatch, you’ll need to implement Log Monitor instrumentation. This setup redirects IIS and system logs to STDOUT, allowing the awslogs driver to automatically capture and forward them to CloudWatch Logs.
Setting Up Log Monitor and CloudWatch for IIS Logs
Follow these steps to configure Log Monitor and send IIS logs to CloudWatch:
Identify the Log Providers.
Determine the providers to include in the configuration file using:
logman query providers | findstr "<GUID or Provider Name>"
For IIS, you can use:
IIS: WWW Server with GUID 3A2A4E84-4C21-4981-AE10-3FDA0D9B0F83
Create the LogMonitorConfig.json file.
This file specifies which logs to capture. Below is an example configuration capturing system logs, application logs, and IIS logs:
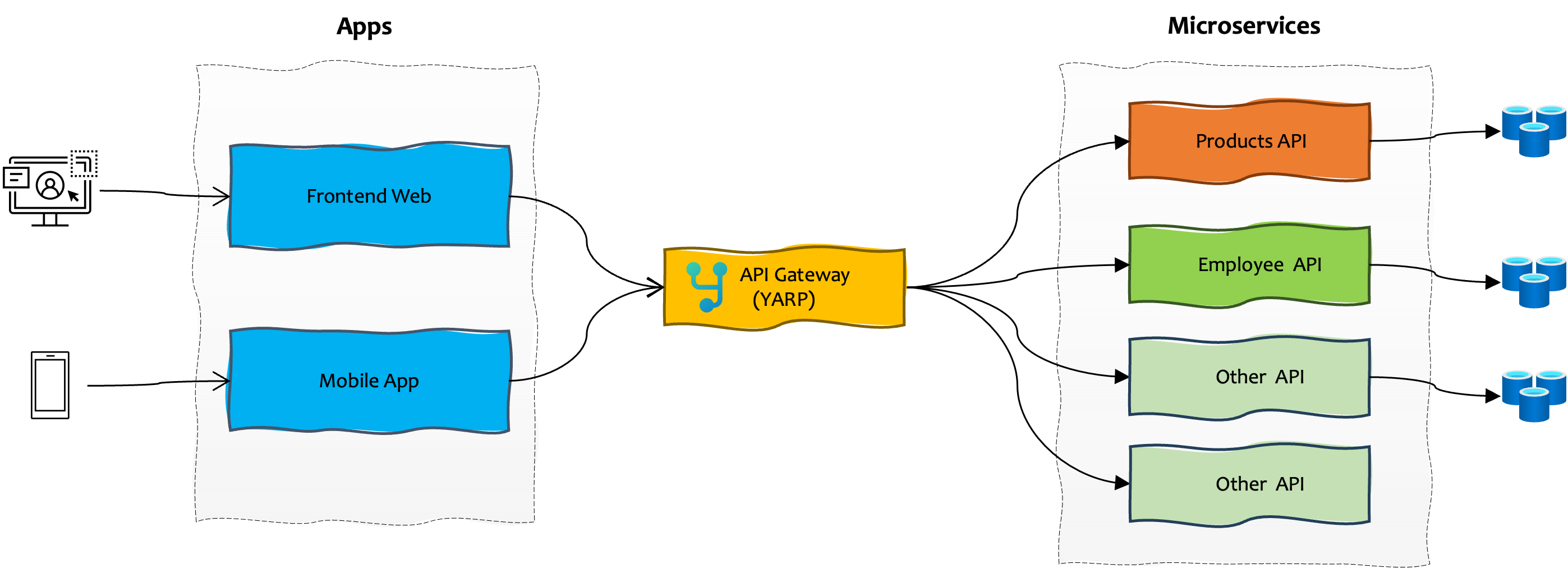
Whenever you are designing an architecture with microservices, you might encounter in how to implement an API Gateway, since you need a way to communicate and consume multiple services, generally through APIs. A possible solution is to have a single entry point for all your clients and implement an API Gateway, which will handle all the requests and route those to appropiate microservices.
There are different ways to implement an API Gateway or pay for built-in services in cloud hostings.
In this post I will pick the easiest way that I found to create one for a microservice architecture using .NET and YARP. Here is a general overview of a microservice architecture.
YARP
YARP (which stands for “Yet Another Reverse Proxy”) is an open-source project that Microsoft built for improving routing through internal services using a built-in reverse proxy server. This become very popular and was implemented for several Azure products as App Service.
To get started, you need to create an ASP.NET core empty project. I chose .NET 7.0 for this post.
To add the YARP configuration you will use appsettings.json file. YARP uses routes and clusters, regularilly inside ReverseProxy object defined in builder configuration section. You can find more information about different configuration settings here.
In this example, I am using Products and Employee microservices. So I will have routes like employee-route and product-route and clusters as product-cluster and employee-cluster pointing to destinations. Open your appsettings.json and apply the following configuration.
In scenarios that you need to allow CORS to specific origins you can add a cors policy described in this Microsoft Doc. Here is a configuration example:
Finally if you want to get more information about YARP logging for future debugging or production information, you can add the YARP log level (Information,Warning or Error) inside Logging object as followed: